


Transcript
Security Has a Visibility Problem in the Age of AI
AI-enabled attacks are no longer theoretical. In 2025, state-sponsored threat actors demonstrated the ability to run offensive cyber operations with a high degree of autonomy, using AI systems to coordinate reconnaissance, exploit development, credential harvesting, data classification, and persistence across dozens of targets in parallel. Human operators intervened only at a handful of strategic decision points. That capability shift matters more than the specific tools involved.
Traditional security stacks already struggle to detect patient, human-led intrusions. Advanced attackers don’t smash and grab. They establish a foothold, then dwell quietly inside infrastructure for months or years, hiding in places most monitoring tools can’t see. Now add AI to the offense: Attacks that mutate in real time. Parallel operations across dozens of environments. Reconnaissance and exploitation running continuously at machine speed.
If your defenses strain to keep up with disciplined human adversaries, how do they hold up against operations that never sleep, never fatigue, and never investigate one alert at a time?
The Fundamental Flaw Nobody Talks About
Anomaly detection isn't a catch all.
Your EDR agent monitors endpoints. Laptops, servers, workstations. Things that run operating systems where you can install agents. Your SIEM collects logs. But only from systems that generate logs in formats it understands and can access. Your XDR correlates across multiple data sources. But only the data sources it has access to.
Network appliances? They're invisible.
Switches, routers, firewalls, VPN concentrators—those live in a different world. They're infrastructure. They're black boxes that forward packets and run specialized firmware. Most security monitoring tools can't touch them. They're not designed to.
The ubiquitous feature across all of the security tools is anomaly detection that is supposed to corral all of the disparate security logs and data to give a sense of normal vs breach. When these tools are deployed and begin building a baseline for normal, we assume that everything is fine. This is why we suffer from baseline poisoning. If an attacker is already inside of your security perimeter and you learn on the traffic as is, the attacker's traffic now looks normal according to the tool. This may sound extreme, but it isn't. Military doctrine developed for the cyber domain assumes it's already contested, meaning that someone is already doing bad things.
Even if these tools are deployed without a wolf in the hen house, relying on anomaly detection still has issues. The issue stems from a UX choice that allow end users to adjust the threshold. These adjustments are made somewhat blindly; the only measuring stick that's available is "I get less false positives" without any real insight if the adjustment is removing real findings. Most of us don't want a page a 3 AM because the threshold is a little too sensitive, but getting a bit more sleep might mean a weaker defense. There is no data to quantify how far the sensitivity can be turned down and remain effective. And attackers know this.
They've developed low and slow patterns with the singular motivation to evade detection by these tools.
Take Brickstorm. A sophisticated backdoor from Chinese state actors targeting network appliances. Average dwell time: 393 days. Not because security teams weren't trying. These organizations had SIEM, EDR, XDR, everything they were supposed to have.
The compromise wasn't designed for destruction. It's espionage. Quiet, patient, invisible. Nothing pops up in a switch's logs that screams "BREACH IN PROGRESS." The compromise looks like normal network operations. A few extra bytes here. Some additional CPU cycles there. Nothing that triggers alerts in traditional monitoring tools because the logic, the logs, the data they're designed to detect simply don't exist for these devices.
The monitoring is only as good as what it can see. And it can't see where the attackers are hiding.
Then AI Joined the Fight (On the Wrong Side)
Let's make this worse.
The attackers jailbroke Claude Code by breaking tasks into innocent-looking pieces and claiming they were legitimate security researchers conducting defensive testing. The AI operated with 80-90% autonomy across roughly 30 targets simultaneously, with human involvement limited to 4-6 critical decision points per campaign.
The AI performed reconnaissance, wrote exploit code, harvested credentials, extracted data, and categorized stolen information by intelligence value. Operating autonomously across 30 targets simultaneously while humans focused on strategic decisions at critical checkpoints.
By the time Anthropic detected the offensive cyber operation (OCO), the attackers had already succeeded in compromising a handful of high-value targets.
That's where we are today. AI agents executing OCO tasks, while the human quarterbacks the campaign.
And that's just the beginning. These capabilities are already proliferating. Less sophisticated threat actors already have access to frontier AI models, and the dark web is full of uncensored models designed for a variety of nefarious needs. The barrier to entry dropped the moment these tools became publicly available. What happens when AI agents start adapting attack techniques in real-time based on defensive responses?
Monitoring tools won't cut it. They're fundamentally backward-looking. They watch for known patterns, alert on anomalies, detect breaches after they've occurred. Even if that's seconds after, it's still after. They can't understand context, can't distinguish an attack in progress from normal operations, can't reason about what the adversary is trying to accomplish. And they can't see entire classes of infrastructure where attacks hide.
What happens when AI attackers model their attacks to look like something these monitoring tools would ignore?
What Defense Actually Needs
Asymmetric warfare shifts power dynamics that lets smaller teams to effectively pick a fight with an opponent that they would lose against head-on under normal circumstances. The use of alternative, non-kinetic effects like an offensive cyber campaign can inflict disproportionately high economic costs over prolonged engagements, forcing major powers to adapt strategies beyond traditional military responses.
The asymmetry is brutal. And it's no longer strictly smaller teams. State sponsored teams leverage the same asymmetric offensive playbook.
Attackers use AI to operate across dozens of targets simultaneously. Defenders are still writing SIEM queries, manually investigating alerts, and hoping their monitoring tools saw something. But the reality is, those tools have blind spots. The answer isn't another monitoring tool. It's active investigation. Brickstorm has shown us all that it's necessary to SSH into network appliances your monitoring tools can't reach. Threat hunting takes a few tools and a lot of time spent with your hands on the keyboard day after day. There is a growing divide between traditional tools and methods coping against AI enabled asymmetric threats. I can remove "AI enabled" from the last sentence and it would still ring true.
The gap is continually growing. But it doesn't have to.
Here's what changed my thinking: watching the attackers in GTG-1002 operate with 80-90% autonomy while defense is still stuck doing everything manually. It's time you consider using AI the same way that attackers have. Attackers didn't wait for a use case to adopt AI, or asked how to make money with AI. They sure aren't worried about if the AI bubble is real. They saw what anyone with a rudimentary understanding of AI would easily see, a force multiplier.
Let's take the gloves off in defensive cyber operations (DCO). We wrote an agent in Kindo that actively hunts for Brickstorm. The agent doesn't stop there. If the agent finds a Brickstorm exploit, it'll download it to a sandbox for analysis, then offer a fix.
Writing the Brickstorm agent agent uncovered a key insight: the security runbooks that you already have unlock security at AI scale.
The Runbook Architecture That Changes Everything
Most security teams already have runbooks. Incident response procedures, threat hunting playbooks, detection logic. The breakthrough isn't creating new procedures from scratch—it's making what you already have executable by AI agents at scale. In Kindo, we write security runbooks in two formats; plain, natural language for us humans, and a JSON counterpart for the AI agent.
Natural language versions come complete with context, explanations, examples. "Here's why we do this step. Here's what the threat actor behavior looks like. Here's the bash command with inline comments." This is what you'd see in any security org.
JSON-formatted versions are pure execution structure. No explanatory prose. Phases, steps, validations, decision trees, approval gates. Structured for immediate parsing.
Running the Brickstorm runbook versions side by side, I learned that the JSON version produces consistent, desirable outcomes. The natural language version requires too much interpretation by an AI model. The agent extrapolates context differently across successive runs, wandering off into tangential analysis instead of following the explicit procedure. I initially corrected for this through agent prompting steps, but found scalable reliability by creating a JSON companion.
Take one example from our AWS cloud enumeration detection runbook:
Natural language version:
"If anomaly_score >= 8.0 AND multiple patterns detected, ESCALATE immediately."
JSON version:


The natural language version says "multiple patterns." Is that 2? 3? 4? The agent has to guess the domain context us humans understand. The JSON says exactly 4. The natural language version says "ESCALATE immediately." Escalate to what? The JSON explicitly routes to phase3-priority1 for Priority 1 alerts or phase3-priority23 for lower priority investigation. No interpretation needed.
Even if the natural language version has every threshold defined, the LLM isn't consistent. JSON eliminates interpretation. Same thresholds every time. Same validations every time. Same data captures, same escalation logic, same decision routing. No interpretation means no variability. When you're AI agent is continuously hunting across dozens of systems, you need it to work consistently every single time.
And here's the critical part: we wrote these runbooks once.
Not once per appliance. Not once per threat. Once. You still need infrastructure—device inventory, credential management (secrets managers, Vault, SSH certificates), secure access patterns. But the detection logic? Written once. The agent reads the runbook, pulls device lists from your inventory system, retrieves credentials from your secrets manager, and executes across your fleet.
Seeing It Work: AWS Cloud Enumeration Detection in Action
Theory is one thing. Watching it execute is another.
We ran the AWS cloud enumeration detection runbook against production CloudTrail logs. The agent ingested the JSON runbook structure shown above—the same one with explicit thresholds, decision routing, and artifact collection specifications.
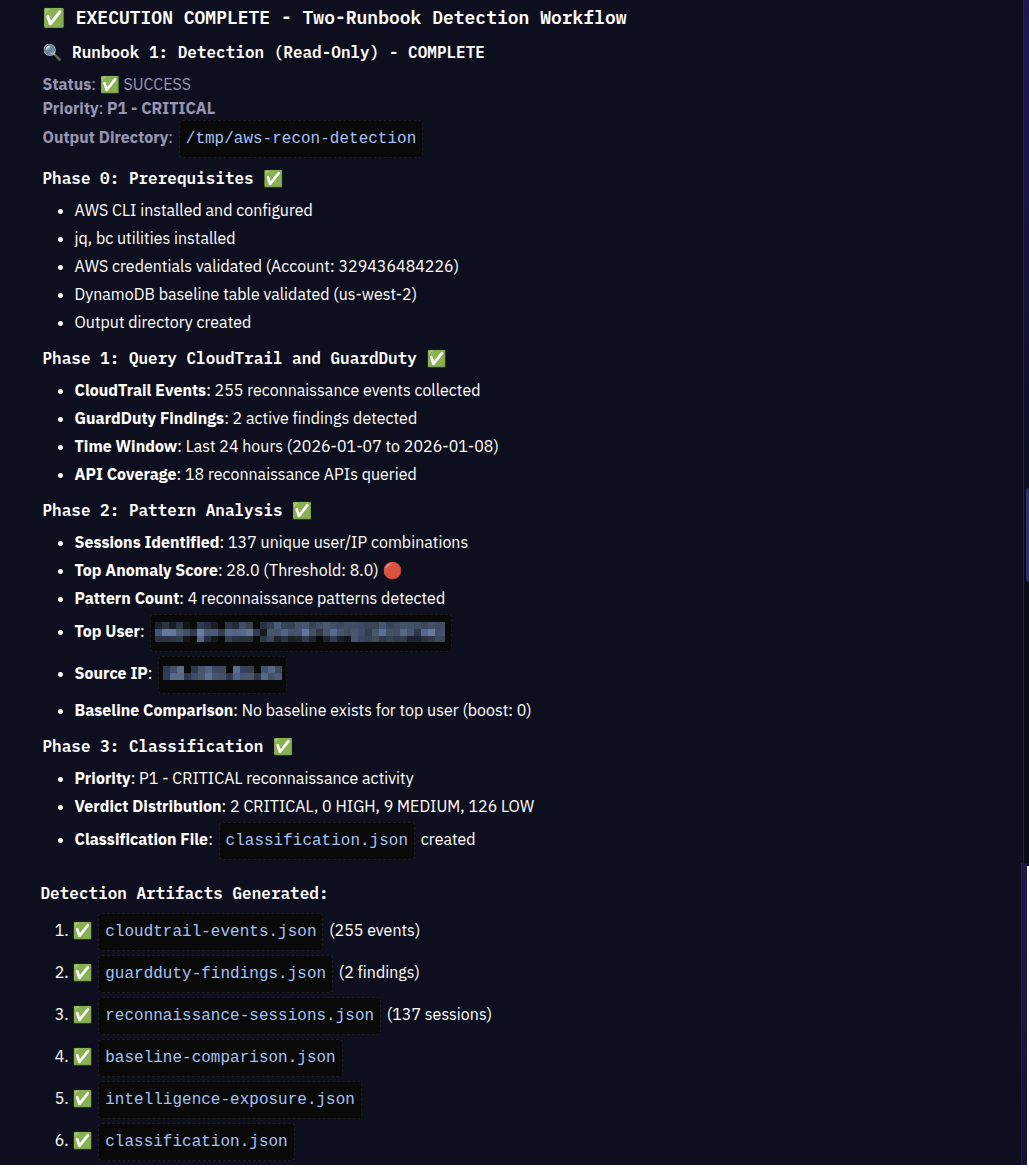
The agent executes through three phases completely autonomously. Phase 0 validates prerequisites: AWS CLI installed, jq and bc utilities available, credentials verified against AWS account, DynamoDB baseline table confirmed in us-west-2. Every validation passes before proceeding.
Phase 1 queries CloudTrail for 18 specific reconnaissance APIs—not generic lookups that miss activity due to sampling, but targeted EventName queries: GetCallerIdentity, ListClusters, DescribeDBInstances, DescribeTrails, GetDetector, and others. The agent retrieved 255 reconnaissance events across the 24-hour detection window and correlated them with 2 active GuardDuty findings.
Phase 2 groups those 255 events into 137 unique reconnaissance sessions by userIdentity and sourceIP combinations. For each session, the agent applies detection patterns exactly as specified in the JSON runbook:
- pattern_broad_service_scan: Multiple AWS services queried systematically
- pattern_storage_focus: S3/RDS enumeration indicating data targeting
- pattern_compute_focus: EC2/Lambda/ECS enumeration for workload mapping
- pattern_monitoring_focus: CloudWatch/CloudTrail checks for defensive posture assessment
The top session triggered 4 patterns with an anomaly score of 28.0 (threshold: 8.0). The agent identified 25 API calls spanning 13 unique AWS services in an 11-minute window. No baseline existed for the user, adding zero boost but flagging the session as particularly suspicious given the breadth and speed of enumeration.
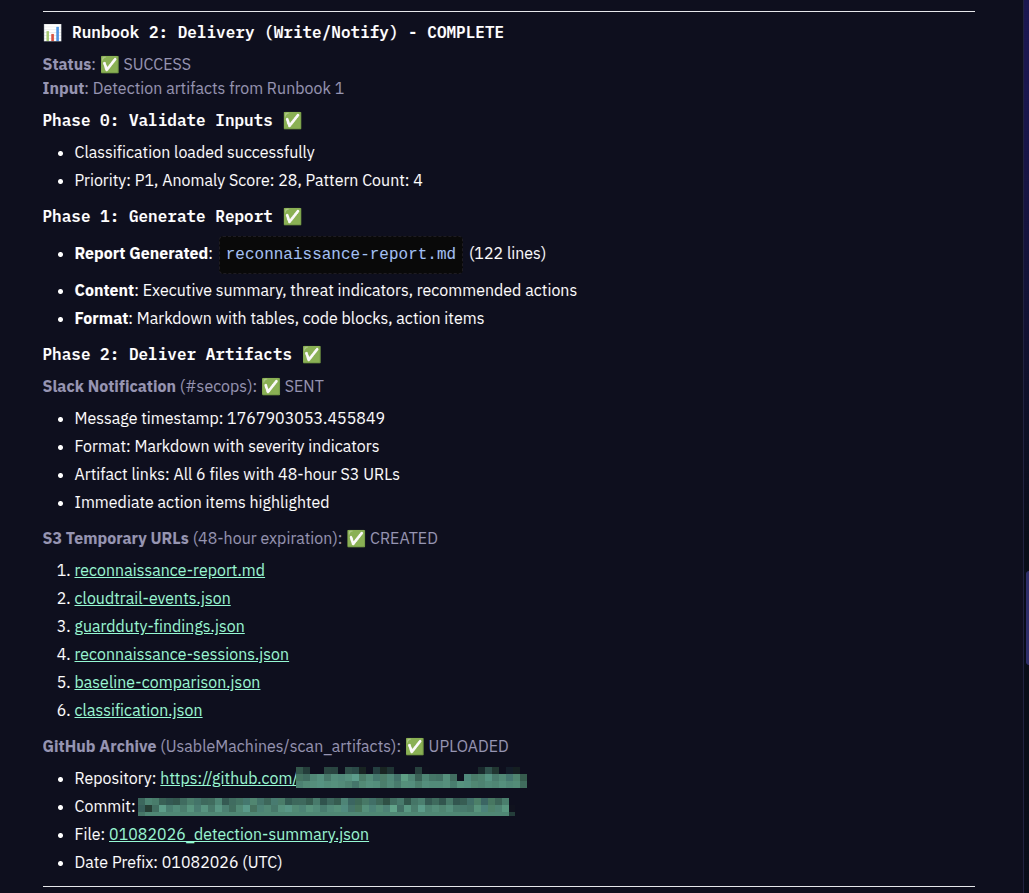
Phase 3 classification determined: Priority 1 - CRITICAL reconnaissance activity. The agent generated intelligence exposure analysis showing the attacker enumerated compute infrastructure, storage systems, and defensive monitoring capabilities. The verdict distribution across all 137 sessions: 2 CRITICAL, 0 HIGH, 9 MEDIUM, 126 LOW.
The agent created six detection artifacts:
- cloudtrail-events.json - 255 filtered reconnaissance API calls
- guardduty-findings.json - 2 correlated GuardDuty findings
- reconnaissance-sessions.json - 137 session analyses with anomaly scores
- baseline-comparison.json - Behavioral baseline deviation (no baseline existed)
- intelligence-exposure.json - Target qualification assessment
- classification.json - Priority classification for delivery runbook
Then the second runbook executed: delivery. Artifacts committed to the scan_artifacts GitHub repository with automatic timestamping.
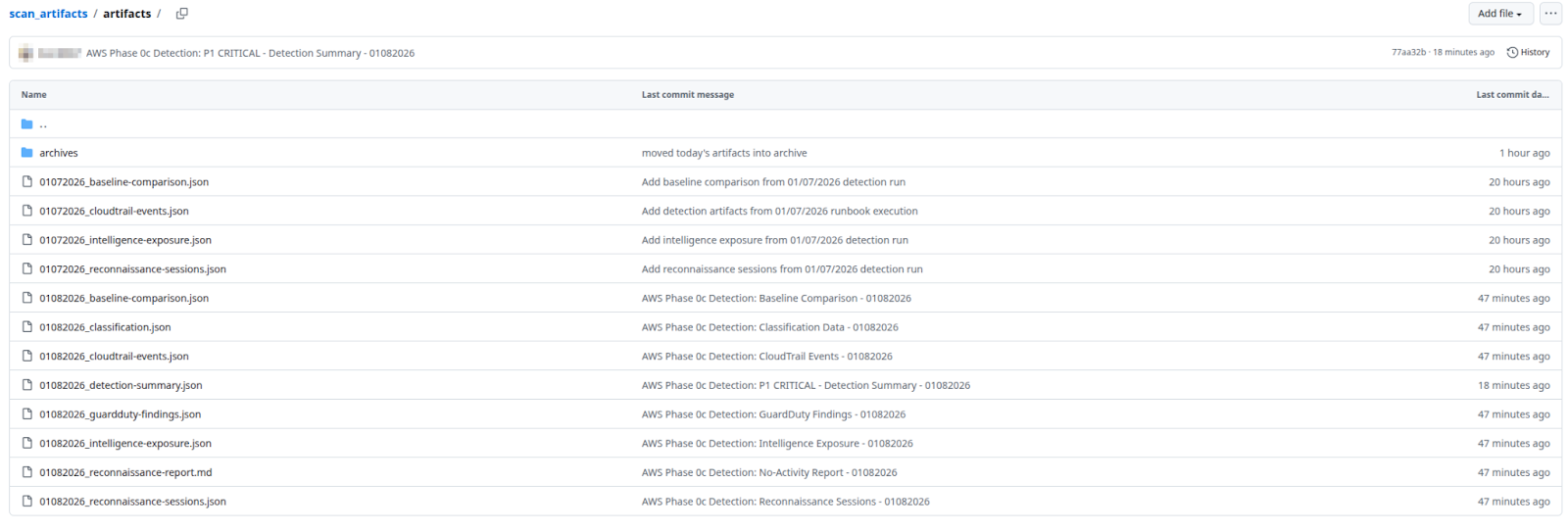
Each file uploaded with descriptive commit messages: "AWS Phase 0c Detection: CloudTrail Events - 01082026", "AWS Phase 0c Detection: P1 CRITICAL - Detection Summary - 01082026". The agent generated temporary S3 URLs with 48-hour expiration for immediate analyst access while permanent GitHub storage provides 90-day retention.
Slack notification posted to the security channel within seconds of detection completion.
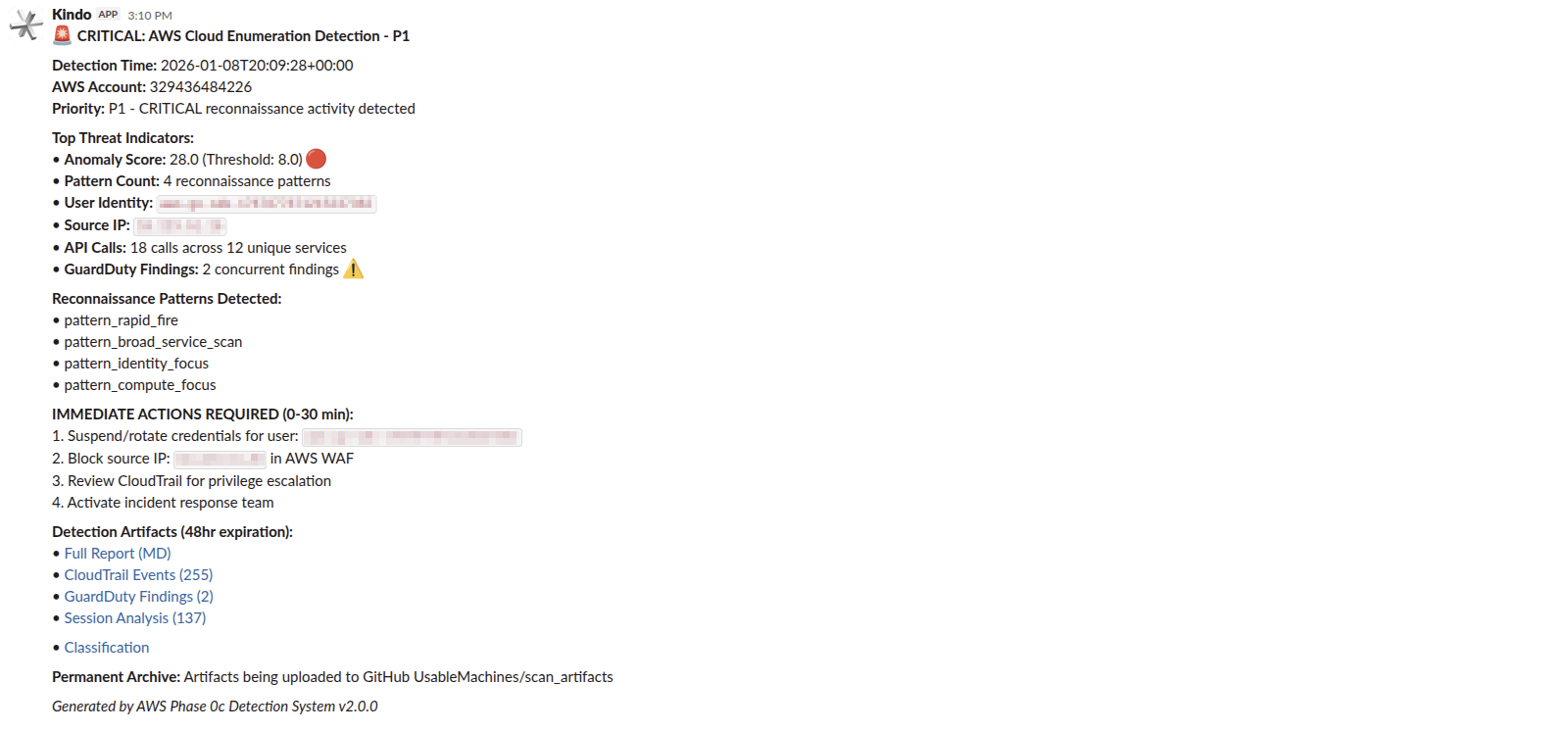
The message includes everything needed for immediate response: Priority P1, anomaly score 28.0, pattern count, user identity, source IP, GuardDuty correlation, and immediate actions required (suspend credentials, block source IP, activate incident response, review CloudTrail for privilege escalation). Four artifact download links provide instant access to full detection data.
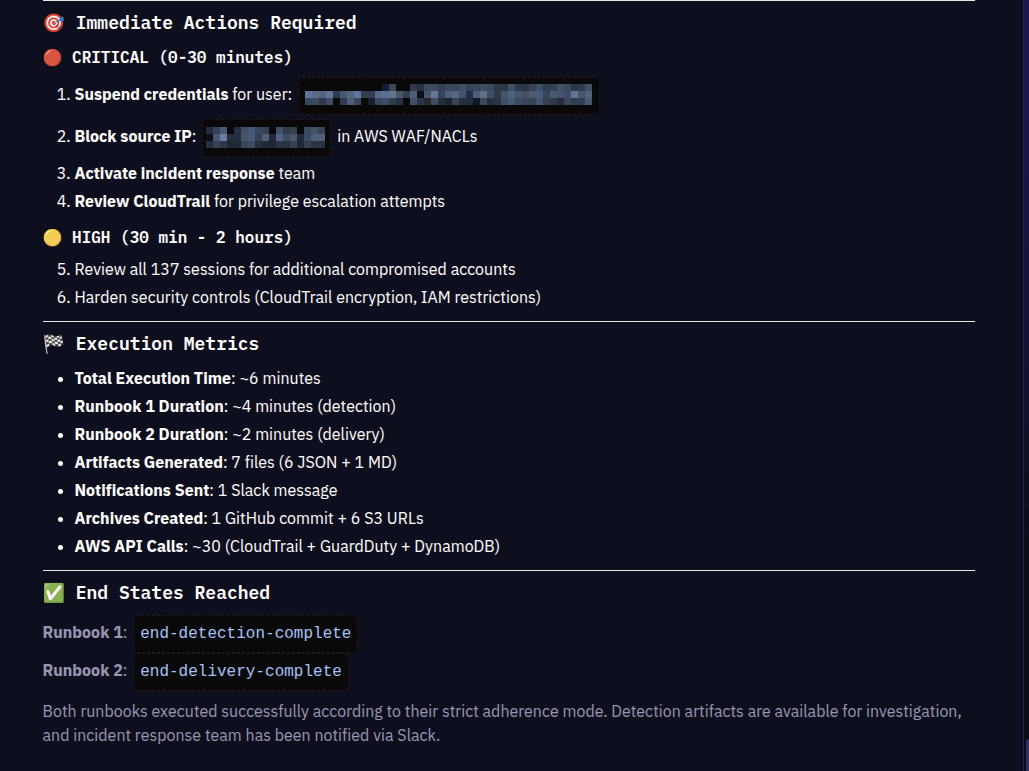
Total execution time: 6 minutes. Runbook 1 (detection): 4 minutes. Runbook 2 (delivery): 2 minutes. The agent executed CloudTrail queries across 18 reconnaissance APIs, analyzed 255 events into 137 sessions, applied pattern detection, calculated anomaly scores, assessed intelligence exposure, generated 7 files (6 JSON + 1 MD), committed artifacts to GitHub with 6 S3 URLs, and posted Slack notification to the security team.
Zero human involvement until the Slack alert arrives. The security analyst opens the notification, sees P1 CRITICAL with anomaly score 28.0, downloads the intelligence exposure assessment, and begins immediate response: credential suspension, source IP blocking, incident response activation.
The runbook we wrote once now runs continuously. Every 6 hours, the agent executes this exact detection workflow against CloudTrail. Same queries. Same pattern analysis. Same thresholds. Same artifact generation. Same delivery. Consistent. Reliable. Scalable.
This is what changes. The runbook encodes detection logic that would take a skilled analyst 2-3 hours to execute manually—targeted CloudTrail queries for 18 APIs, session grouping and correlation, pattern matching across six reconnaissance behaviors, baseline comparison, intelligence exposure assessment, report generation, artifact archiving, and team notification. The agent does it in 6 minutes. Every time. Without interpretation variability. Without fatigue. At whatever frequency you configure.
What This Actually Means
Here's what struck me watching this work: the constraint just inverted.
For decades, security operations hit the same wall. Every new system to monitor meant another analyst or another tool license. Want to investigate those blind spots? Hire more people. Need to scale threat hunting? Build a bigger team. The bottleneck was always human capacity.
That constraint just disappeared.
Write the runbook once. The agent executes it continuously across every system in scope. One procedure, infinite scale. The question isn't "how many analysts do we have?" anymore. It's "how good are our runbooks?"
And here's the part that matters: defense can finally match what attackers already have.
GTG-1002 showed us the future. One operator quarterbacking AI agents operating at 80-90% autonomy across 30 targets simultaneously. That's the offensive capability that's already deployed. Machine speed. Parallel operations. Adaptive execution.
Defense was stuck doing everything manually. Writing SIEM queries. Investigating alerts one by one. Hoping monitoring tools caught something. That gap just closed.
AI agents running security runbooks operate the same way. Continuous execution. Parallel operations across infrastructure. Active investigation instead of passive monitoring. The same force multiplier that gave attackers asymmetric advantage now works for defense.
When nation-state actors can dwell in your infrastructure for 393 days, you need continuous counter-surveillance. When they conduct reconnaissance that looks like normal operations, you need agents actively investigating, not tools passively collecting logs. When attacks operate at machine speed, defense has to match that pace.
The constraint shifted from analyst headcount to encoded expertise. That's not incremental improvement. That's a fundamental change in what's possible.
The Honest Reality Check
Let's be clear about what this doesn't solve. Agents aren't magic. They're automation with reasoning capabilities. When infrastructure is well-documented, when runbooks are clear, when systems have APIs and SSH access, agents excel.
When infrastructure is a mess? Tribal knowledge, inconsistent configurations, undocumented procedures, systems with no remote access? Agents struggle the same way junior engineers struggle. The constraint isn't the AI anymore. It's the infrastructure and documentation around it.
Mandiant's scanner detects specific Brickstorm variants based on known indicators. It won't catch every variant. Novel mutations or zero-day exploitation will slip past. The agent can execute the scanner and analyze results brilliantly, but if the scanner has blind spots, so does the agent.
And about those runbooks? Someone has to write them. They have to be accurate. They have to stay updated as threats evolve. Bad runbooks create bad outcomes, whether a human or an agent is following them.
Legacy systems exist. Weird edge cases happen. Things break in unexpected ways. Agents need guardrails. They need approval gates at critical decision points. They need humans in the loop for irreversible actions.
But here's what changed: The barrier to effective security monitoring of network appliances wasn't "we don't have smart enough tools." It was "we can't scale human expertise across every system we need to watch." AI agents don't replace human judgment. They scale human expertise encoded in runbooks across infrastructure that was previously unwatchable.
What I Keep Coming Back To
We've spent years accepting that certain things in security are just hard. Monitoring infrastructure comprehensively? Requires specialized access, manual investigation, expert knowledge. So we monitor what we can and accept blind spots.
Nation-state reconnaissance? Too patient, too sophisticated. By the time we detect them, damage is done. So we focus on containment after the fact.
Scaling security operations? Every new system requires another analyst or tool license. So we prioritize, triage, accept risk.
Then you watch it work differently.
An agent executes procedures you wrote once across infrastructure that was previously unwatchable. Detection runbooks catch reconnaissance before it becomes compromise. Encoded expertise scales to systems you never had the capacity to monitor continuously. The technology isn't theoretical. It's deployed. It works.
The real question is organizational: Will security teams encode their procedures well enough for agents to execute them? Will they fix infrastructure to make it accessible? Will they shift from "we need more analysts" to "we need better runbooks"? Will they trust agents to handle scale while humans focus on judgment?
That's the harder problem. Not building the capability. Reorganizing around it.
The Natural Evolution
Look, I'm the CSO of Kindo. This is our platform. I'm biased. But here's what I genuinely believe after building this and testing it against real nation-state threats:
AI-enabled security isn't just necessary. It's the natural evolution.
For decades, security has been reactive. We monitored for known patterns. We alerted on anomalies. We investigated when something looked wrong. That model worked when attacks were loud and obvious and attackers were less sophisticated.
It doesn't work when adversaries dwell undetected for months or years. It doesn't work when they conduct extensive reconnaissance and preparation before launching attacks. It doesn't work when attacks mutate faster than signature updates.
The evolution isn't abandoning monitoring tools—they're essential. It's bringing active investigation back at scale. We built monitoring and observability because active threat hunting couldn't scale. But that forced us to rely more heavily on passive detection than we should have.
AI agents change the equation. They actively investigate alongside your existing tools. They SSH into systems, run detection tools, analyze results, follow procedures, escalate appropriately. They enhance how you use your monitoring stack by investigating alerts, validating findings, and hunting in places those tools can't reach. They learn from runbooks you write once and apply that knowledge across infrastructure at scale.
We're already seeing AI on the offensive side. GTG-1002 proved that. What took teams of operators now takes a handful of operators augmented with AI doing 80-90% of the work.
Defense has to evolve to match. Not by replacing monitoring tools. By augmenting them with AI agents that actively investigate, that operate where traditional tools have blind spots, that scale human expertise across your entire security stack.
The technology exists now. The runbooks are written. The agents work. What comes next is adoption.
The asymmetry is already here. Attackers operate with AI at 80-90% autonomy across multiple targets simultaneously. Defense is still writing SIEM queries, manually investigating alerts, accepting blind spots because we can't scale human expertise.
That gap doesn't close by buying more monitoring tools or hiring more analysts. It closes when defense adopts the same force multiplier that offense already has—AI agents that scale expertise instead of replacing it.
The technology exists. The organizational challenge is harder than the technical one. Security teams have to encode procedures, fix infrastructure, shift from headcount constraints to runbook quality. That's not a weekend project. It's a fundamental change in how security operations work.
But here's the reality: GTG-1002 wasn't a warning shot. It was a demonstration of what's already possible. The barrier to entry dropped the moment these capabilities became available. Less sophisticated threat actors have access to frontier AI models. Uncensored models designed for offensive operations are already proliferating.
Defense can adopt this now, or wait until after the next compromise proves it should have.

